
Comment systems are used all over the Internet especially on blogs. These are pretty wide ranging from popular hosted freemium versions like Disqus to open source self-hosted options like Commento. If you are looking to use an open source version, then the hosting of these seem restricted to traditional server-based hosting options and there aren’t many real options exploiting the opportunities serverless has to offer.
In this post, we will create a simple serverless comment system to be used on a blog. Creating an application serverlessly has many benefits; reduced costs, little/no maintenance, a faster pace of development, implicit scalability, the list goes on. This example application will use some technologies provided by AWS to create a comment system that will be able to list comments from other users, post new comments and display posts from other users in real time.
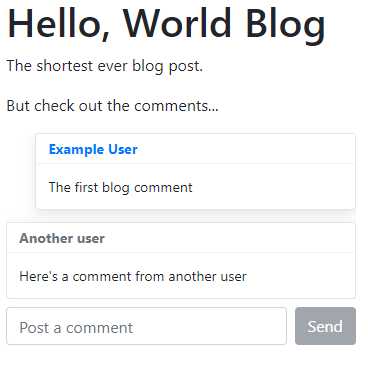
The building blocks
Let’s start with an overview of the technology that we will use to build our simple app. The front-end application is built using React and is intentionally simple to just demonstrate the capabilities of the serverless back-end, so we won’t discuss that in detail.
All of our data is going to be stored in 3 tables in DynamoDB:
users: storing all our usersblogs: storing all our blogscomments: storing all the comments about all of our blogs
To transfer the data between our app and the tables we will use AWS AppSync. It will allow us to update and retrieve the data from DynamoDB easily using GraphQL as a schema. An additional feature that will be a benefit to us is that it has WebSocket support to enable it to push out new comments to any subscribers of a blog post in real time.
This is the flow of components from our application to where the data is stored:

Let’s look at each of these components a little deeper.
DynamoDB
DynamoDB is AWS’s NoSQL database. It’s where we will store our data. It comes with more features then we will need for our simple application, but the benefit is that if the system becomes popular then we are in the position that we can grow easily to accommodate it.
Some of the key features are:
- Fast read/write: It can handle millions of requests a second with millisecond response times
- Scalable: It can scale from a few requests to millions and this can be set up to scale automatically
- Security: All the data is encrypted at rest on the AWS disks and the communication between DynamoDB and AppSync is also encrypted. This is all on by default and completely transparent
- Caching: I am not using this but if needed, results can be cached to improve response times (resulting in single digit milliseconds responses) and reduce the number of queries that are needed to be run (reducing cost)
AppSync
This is the communication layer between our front-end application and the DynamoDB tables. It allows applications to call the API with a schema defined using GraphQL and then maps these requests onto a variety of different data sources. For this example, it is straight onto DynamoDB but it also able to connect to AWS Lambdas, relational databases, and other HTTP endpoints. As I mentioned earlier it supports WebSockets to update subscribers to the API in real time and can support off-line applications.
Some of the key features are:
- Scalable: It can handle almost unlimited requests without the need for you to actively do anything. You just have to make sure the data sources it connects to can handle it, as most of these are also AWS serverless applications then you are covered here as well
- Security: You can only communicate with AppSync via HTTPS and it has easy integration into a variety of authentication and authorisation mechanisms, like AWS Cognito
- Easy to setup (sort of): It takes away some of the traditional complications of setting up servers and the challenges of creating the connections between all of the different data sources using a GraphQL schema. It just takes a little getting used to writing the resolvers (more on those later)
GraphQL
This is the schema of our API, it is how our application knows how to call the API and provides AppSync with the information it needs to answer. It was originally developed by Facebook as an alternative to REST APIs as it gives the caller more power to ask for what they want and for the API to change over time without the need for versioning.
It allows us to define types in the schema, for example here is the definition of a blog:
type Blog {
blogId: String!
comments: [Comment]
}
It has the ID of the blog which is a mandatory type of string (the exclamation mark makes it mandatory) and an array of Comments which is another type that has been created in the schema.
We can then describe the calls that can be made to query our system using a special Query type:
type Query {
getBlog(blogId: String!): Blog
}
This says that we have a method we can call to getBlog which will retrieve an item of the type Blog given its ID.
The caller of this API then has the flexibility to call this method how they like and just retrieve the data they are interested in, for example:
query getBlog($blogId: String!) {
getBlog(blogId: $blogId) {
blogId
comments {
commentId
userId
posted
message
}
}
}
This is a parameterised query allowing a blogId to be passed in and it returns all of the details about the comments; the ID, the user when it was posted and the message. A different user who is only interested in getting just the message bodies from the blog with the ID of test-id could write this query and ignore the other fields:
query getTestBlog() {
getBlog(blogId: "test-id") {
blogId
comments {
message
}
}
}
This flexibility allows the calling applications to define what they are interested in receiving in the response using exactly the same method on our schema. It also allows the schema to evolve over time, for example, if we wanted to include a title on the Blog type then we could just add it and all of the existing callers would still continue to work as they haven’t specified they want it in their responses.
Data Sources
This is a component of AppSync and is pretty simple. All it does is provide details for AppSync on what sources are available to be called and what permissions it has on those objects. These sources can be AWS Lambdas, relational databases, AWS Elasticsearch, HTTP endpoints and of course DynamoDB which is the one we are using.
Resolvers
These are another component of AppSync. This is the part that connects the GraphQL schema to the data sources. Each component of the schema can be assigned a resolver that is connected to a data source. A template is written in Apache Velocity Template Language (VTL) to convert the request into something DynamoDB can understand and convert the response back to something matching the GraphQL schema. AppSync is then in control of actually executing against DynamoDB and taking the correct parts of the response out to match the callers’ request.
Here is an example of what is mapped from the getBlog query in the GraphQL schema to the blog table in DynamoDB:
{
"version": "2017-02-28",
"operation": "GetItem",
"key": {
"blogId": $util.dynamodb.toDynamoDBJson($ctx.args.blogId)
}
}
It is a template that creates a GetItem request (something that is understood by DynamoDB) and tells it which blog to return based on the ID that is an argument from the getBlog query we saw earlier in the GraphQL schema.
This query will actually return the entire object from the table with all its fields. The response mapping template just converts this to JSON for AppSync:
$util.toJson($ctx.result)
Even though this returns more fields then the caller may have requested, AppSync will shape the data and return just the ones the caller asked for.
Have a look yourself
If you are interested in taking a look at the code yourself, then it is hosted in Github. To run it all you need is an AWS account and you’ll be able to create all of the AWS services preconfigured using the CloudFormation template in there and run the simple React application locally to see it in action.
Taking it further
The application I created was pretty simple, but it demonstrates how to use AppSync and DynamoDB to create a serverless comment system that pushes data to other users in real time.
It wouldn’t take too much more to make this a little more production ready, obvious things like adding better security would be useful and the easy integration between AppSync and AWS Cognito (AWS’s user management system) would be good enhancement without much additional effort.
The one thing that is great even from an example as simple as this, is that it is ready to become something used at much greater volumes. AppSync and DynamoDB are built to handle thousands of concurrent requests easily and this doesn’t have some of the development and hosting challenges normally faced by that kind of problem. It also has great cost benefits too. The application in its current state is within the AWS free tier so it won’t cost anything at low volumes of use. Even if it does scale to large volumes (and they would have to be quite large) then you only pay for what you use, no paying for capacity you don’t need during quiet times.
Overall, I think AppSync is a great tool and provides some nice features for developing APIs.

