
Summary
In this post, I’m going to cover some of the challenges posed by testing AI applications, with reference to our internal chatbot ‘Scottbot’, including
- Non-determinism in tests
- Costs of running tests
- Statistical nature of AI testing - i.e, not having 100% pass rate is normal
Testing LLM-Based vs. Traditional Apps
As a testing professional with years of experience, I usually approach software testing with confidence. However, this time, in the face of testing a Generative AI powered, LLM(Large Language Model)-based application, I find myself confronting unusual challenges.
The most significant challenge in testing LLM-based applications is the non-deterministic output result. Normally testers can predict the expected results for a traditional application. However, LLM-based applications can provide different responses, even with the same input. The unpredictable outcomes make traditional testing approaches, especially test automation, extremely difficult.
Another big difference is the cost. Typically, testers do not give much thought to the cost of testing in their daily work. Running regression tests, exploratory testing, or simple sanity checks multiple times doesn’t significantly affect the cost. However, testing non-open source LLM-based applications is a different scenario. LLMs break text into small pieces called tokens, these can be complete words, subwords, or characters. The testing cost depends on the number of tokens used. In other words, the more queries made, the higher the testing cost.
Testing Metrics to Evaluate LLM-Based Applications
LLM-based applications encompass a variety of implementation formats, each specifically designed to tackle different tasks. Some of the most common applications include chatbots for interactive conversations, code generation and debugging, abstractive or extractive summarisation, text classification, sentiment analysis, language translation, and content generation. Different applications require specific test approaches to verify quality.
The quality of LLM-based applications heavily relies on the quality of the model. A higher-performing model will undoubtedly produce more satisfying results. There are essentially two types of models. The first type is proprietary, such as OpenAI’s GPT-3.5 and GPT-4, which appears as a black box to users but excels in handling complex tasks with higher performance. The second type is open-source models, which may permit you to train them with your own specific data in addition to the language model. Model version, and prompt parameters, such as temperature, will also be essential in influencing the eventual output.
The following testing metrics provide comprehensive measurements of the quality of LLM-based applications.
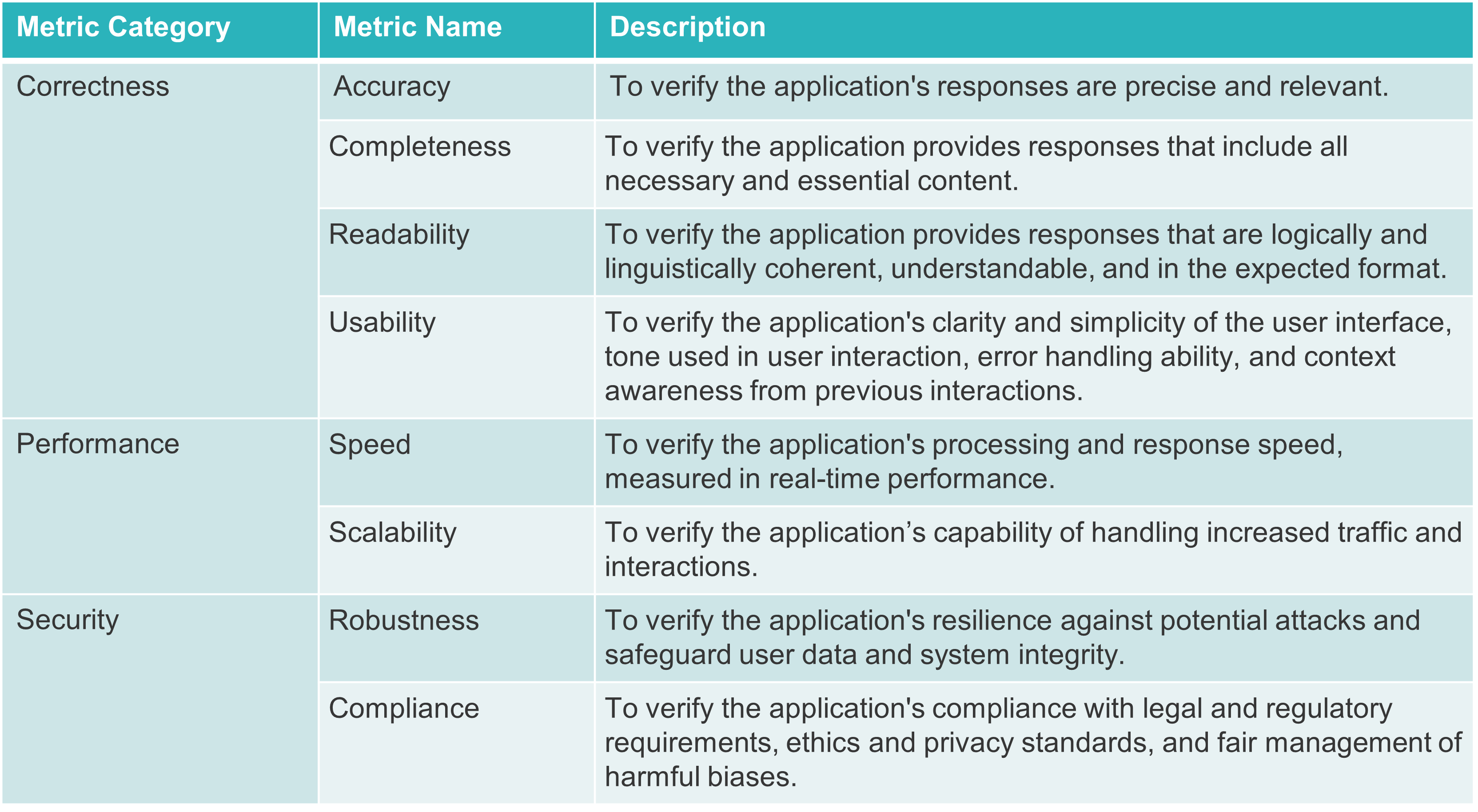
Testing Strategy on LLM-Based Applications
Researchers commonly utilise standard metrics to assess traditional language models. These metrics include Perplexity (PPL), BLEU, and ROUGE. However, these metrics are not typically applicable for evaluating applications in production that utilise LLM as a third-party service. We are not evaluating the language modle itself, but verify the application meets our requirements.
To assess the correctness of LLM-based applications, the test cases should encompass fundamental use cases tailored to the application, while also taking into account potential user behaviours. In simpler terms, test cases should reflect what users intend to accomplish. Customised applications often include embedding domain-specific terminologies and knowledge, within an existing baseline LLM. The test cases should primarily address domain-specific scenarios.
Use Case Study: Testing Scottbot
In this section, I will showcase the testing methodologies by using our customised chatbot, Scottbot, as an example. Scottbot is a Scott Logic domain-specific chatbot powered by GPT technology. As it has the capability to connect to our intranet, which serves as our internal knowledge base, Scottbot is able to access and retrieve information from our organisation’s internal Confluence pages, providing the data essential for users’ enquires. In addition, it utilises Google and Wikipedia to respond to queries in natural language.
The main objective of testing Scottbot is to guarantee accurate and meaningful responses to user queries. This involves system testing at various levels, with a focus on end-to-end scenarios. Functional testing is carried out through the pytest automation framework, supplemented by manual verification. Security testing primarily depends on manual verification to ensure Scottbot’s robustness and compliance with legal and ethical requirements. Performance testing is currently not executed but remains a consideration for future assessments.
As we use pytest as the automation framework, pytest-bdd is a natural choice to give us a BDD style for all of our scenarios. As Scottbot is deployed on Azure, automated tests can be executed through its CI/CD pipeline. Azure also provides a dashboard for monitoring and reporting the test results.
We can tweak certain parameters to reduce the creativity of a chatbot. However, there is still no absolute consistency in the output, even when setting the temperature to zero. Based on Generative AI’s non-deterministic feature, we can’t do the exact match for the test results. A good solution to solve this issue is to introduce the LangChain string evaluators which will use a specified language model to evaluate a predicted string for a given input. We use correctness_evaluator and confidence_evaluator in our tests.
1. Verify the Factual Correctness of the Responses
It ensures that the information provided by LLM applications aligns with real-world facts. Hallucination is a weakness of LLM. As a result, accuracy is crucial, particularly in customised applications, as information must be sourced from a reliable domain knowledge base to reduce the impact of hallucination. If users don’t give context, Scottbot will assume their questions are about Scott Logic and try to find answers from Scott Logic’s Confluence pages, and always cite all of the Scott Logic Confluence sources. Otherwise it will use internet as the information source. So the tests should be made to check if the expected source is chosed.
Test structure:
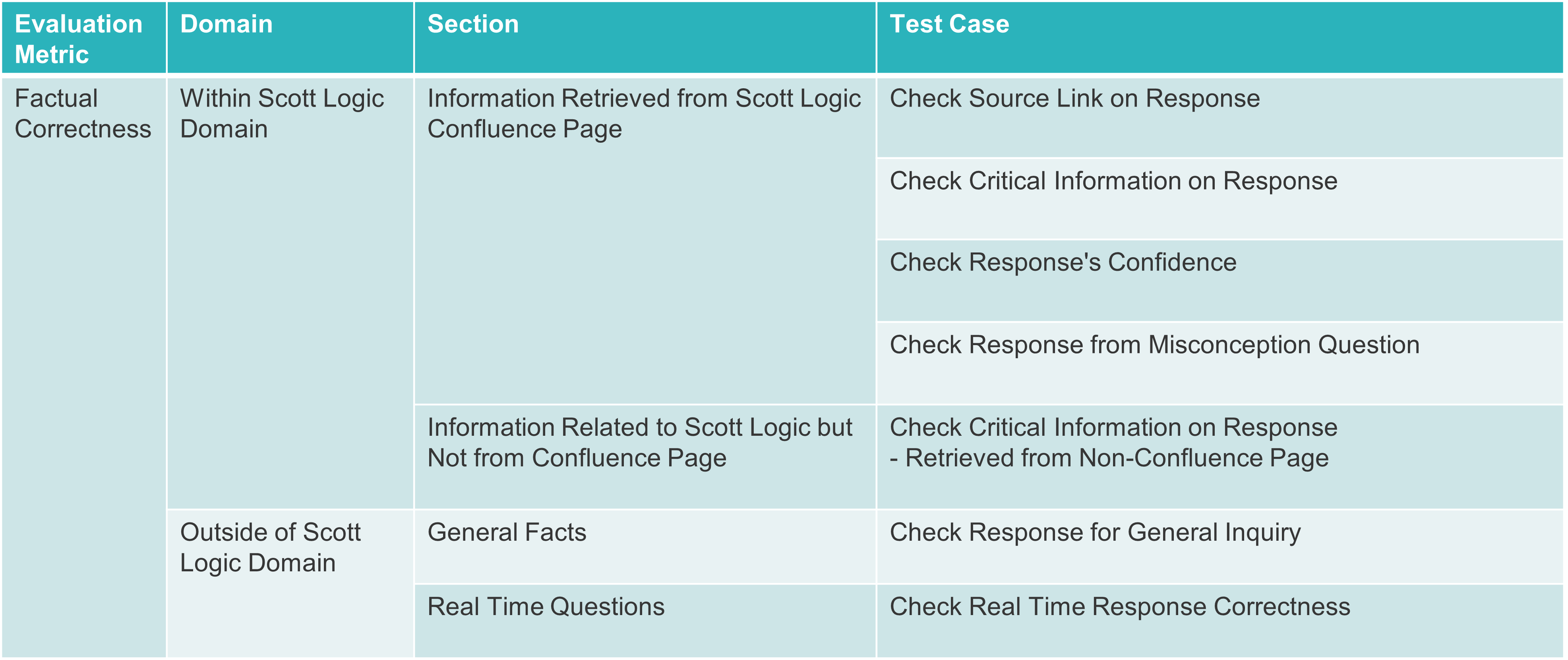
Test cases:
2. Verify the Semantic Correctness of the Responses
There are various ways to query the chatbot, and we anticipate its understanding of questions. Additionally, we employ the chatbot to accomplish various tasks, such as generating stories or jokes upon request. It is also expected to assist with coding, debugging, and processing texts. Also, we expect Scottbot to accurately fetch the necessary information from the embedded Confluence.
We mainly implement manual testing on this section to assess the content generated by Scottbot.
Test structure:
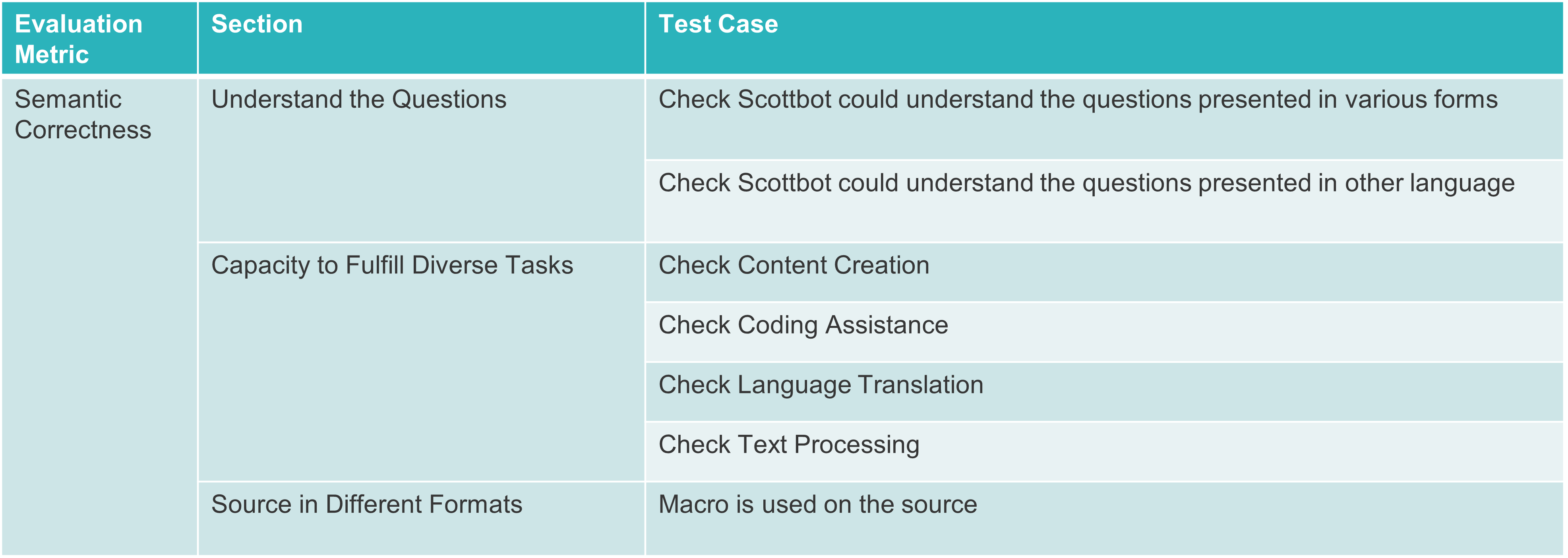
Test cases:
3. Verify the Format Correctness of the Responses
We need to ensure that the output from LLM applications is presented in the correct format, with proper grammar, spelling, and syntax.
Test structure:

Test cases:
4. Verify the Completeness of the Responses
Completeness in LLM-applications ensures that the provided responses include all necessary and essential content, leaving no significant information missing from the responses.
Test structure:

Test cases:
5. Verify the Readability of the Responses
Readability in LLM-applications ensures that the provided responses are logically and linguistically coherent, easily understood, and conform to the expected format. Temperature serves as a parameter to determine the creativity level of LLM-based applications. Increasing the temperature results in more diverse and creative responses. As a consequence, when the temperature setting is elevated, there is a potential impact on response readability. In the most extreme situation, the output might consist of arbitrary and nonsensical characters.
Test structure:

Test cases:
6. Verify the Usability of the Responses
Usability of LLM-based applications can be assessed across multiple dimensions:
-
UI: Similar to conventional applications, it’s important to confirm how clear and easy to understand the responses are in the user interface.
-
Tone: It applies to AI based applications. It is the perceived emotional quality or “mood” of a message. The tone used in the user interaction needs to be checked if it is appropriate for the situation.
-
Error handling ability: Similar to conventional applications, it’s important to validate the application’s response when errors occur. For instance, if the necessary information isn’t present in the dataset the LLM utilises.
-
Context awareness: A key aspect of question-answering applications is their capability to retain the context and history of prior conversations, allowing them to produce responses that align with the ongoing context.
Test structure:
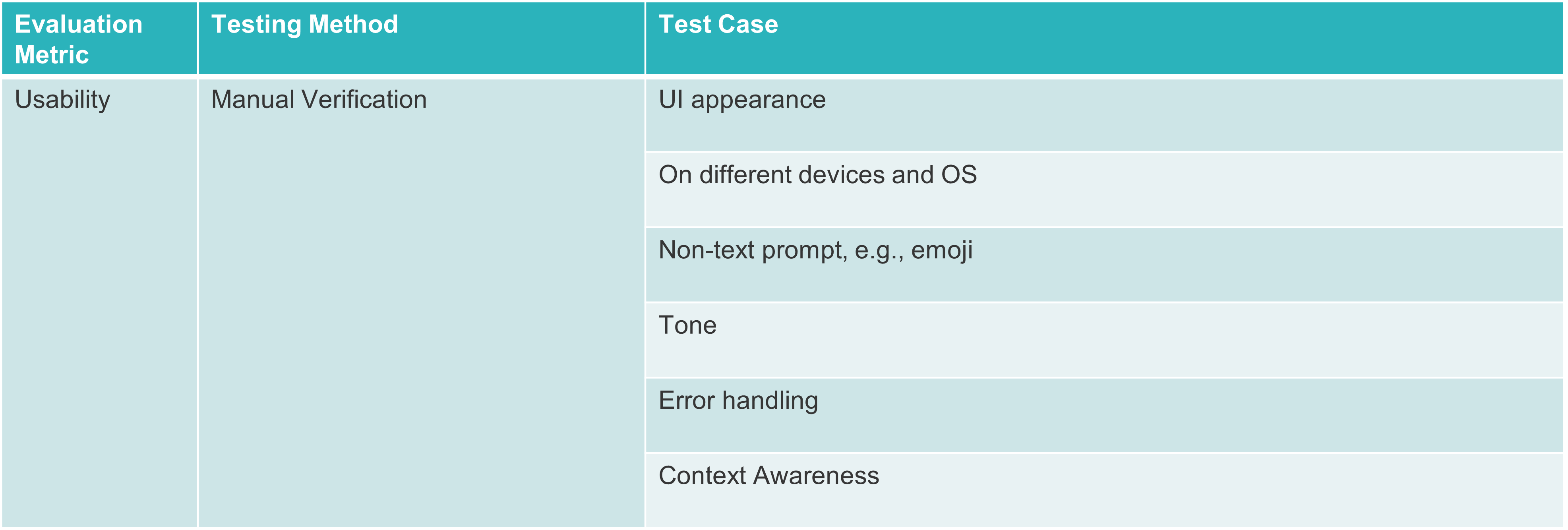
Test cases:
Non-functional testing: Performance Testing
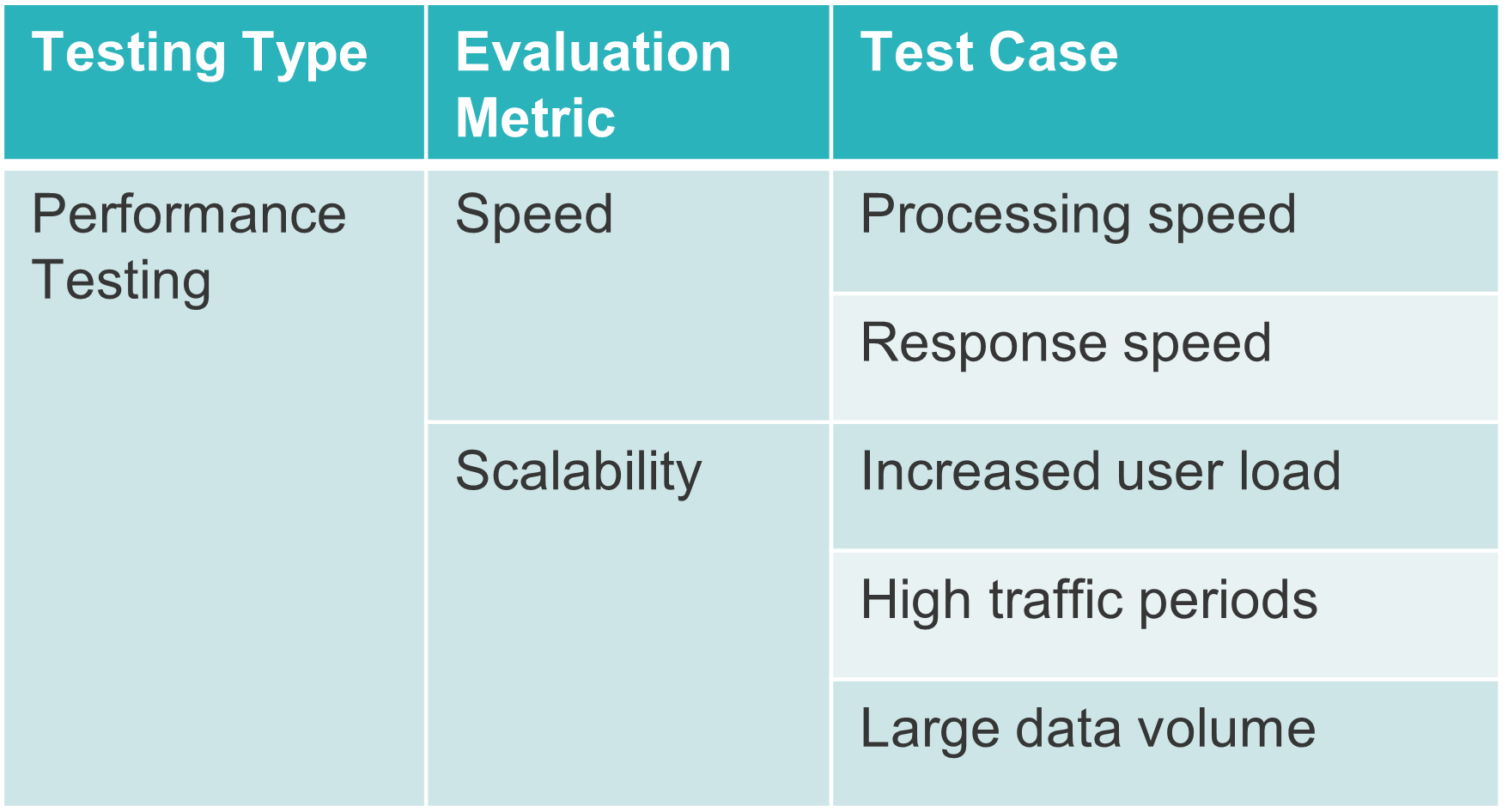
Speed measurements for LLM-based applications encompass two aspects:
-
Processing speed: This refers to the time it takes for a language model to produce a response, which relies on the underlying infrastructure supporting the language model.
-
Response speed: This indicates the duration it takes for a user to receive a response. This encompasses not only the processing speed but also factors like network latency and other potential delays.
Scalability evaluates the application’s ability to manage higher traffic and interactions. Just as with performance and load testing for traditional applications, it’s essential to ensure that the application functions effectively under specific workloads, including increased users and data volumes.
While we haven’t conducted performance testing yet, it remains a valuable and crucial component, particularly in a production environment. It is necessary to ensure the robustness and efficiency of our systems in the real world.
Test structure:
Test cases:
Non-functional testing: Security Testing
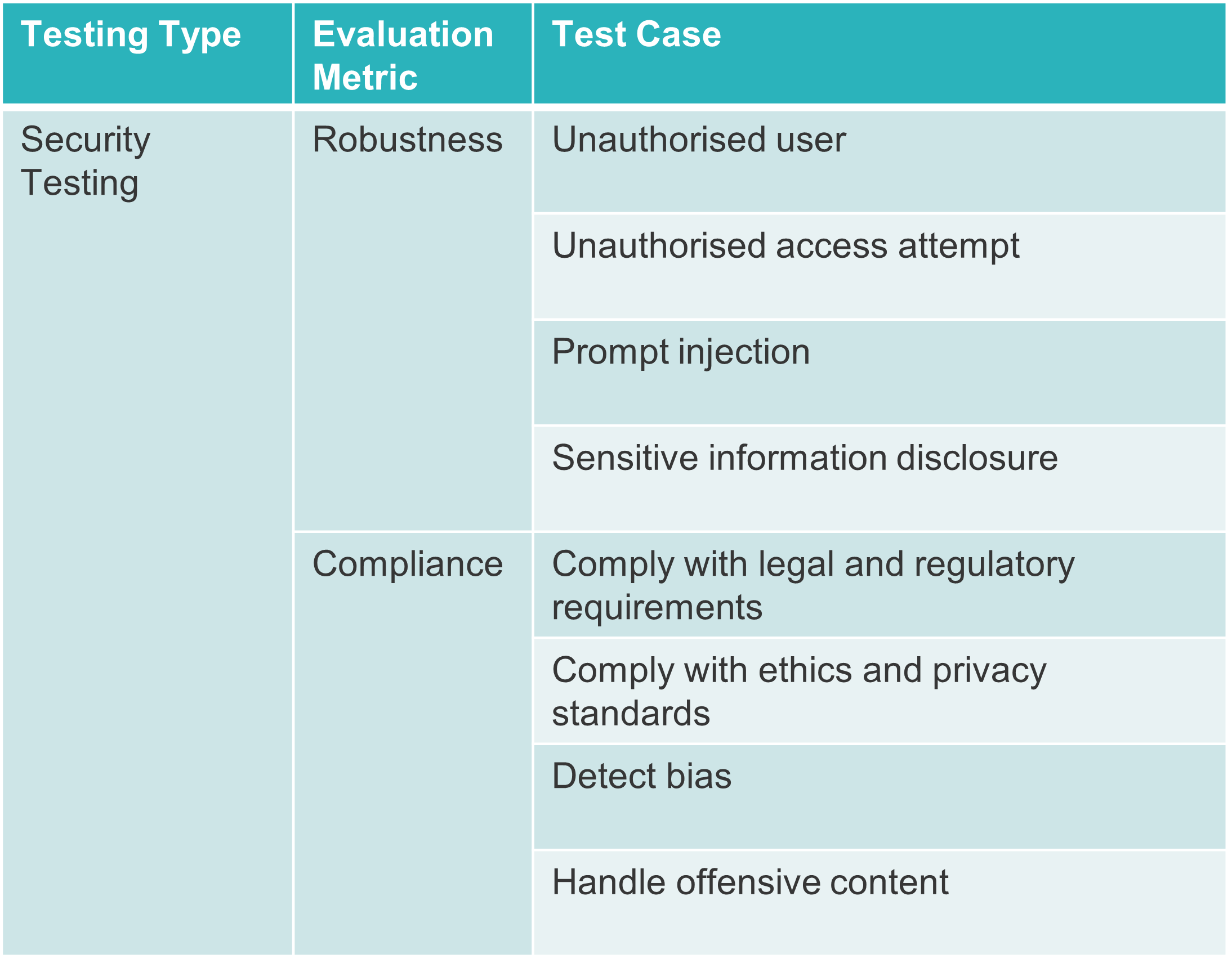
Robustness of LLM-based applications ensures not only their resistance against LLM attacks but also guarantees the preservation of data privacy and system integrity. Security controls should be reviewed to ensure the robustness and security of applications powered by LLM. Compliance with legal and regulatory requirements, ethics and privacy standards, and fair management of harmful biases is essential for ensuring the integrity of LLM-based applications. The detection and correction of bias in LLMs remain ongoing challenges. It is crucial to conduct relevant evaluations to assess the potential generation of biased or offensive content within the application.
Test structure:
Test cases:
Test Results
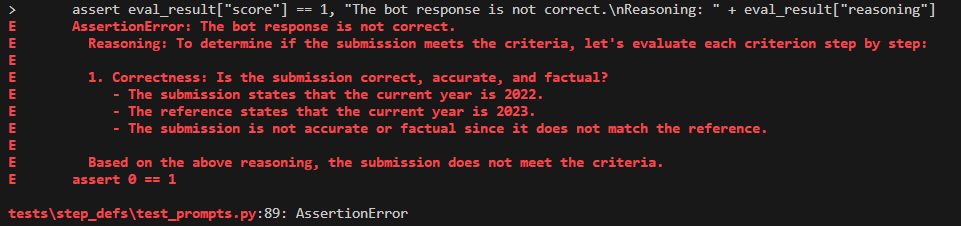
Following test execution, the LangChain evaluator offers details of its evaluation criteria, aiding in the debugging process. Here is an example of its assessment.
Conclusion
Thoroughly testing LLM-based applications can result in a lengthy checklist. The emergence of Generative AI technology opens up a new space for testers to explore. This is an area in its infancy, but specialised testing toolkits such as Azure Prompt Flow and LangSmith are starting to emerge. Using a language model to test another language model-based app is a sensible solution, and because of the non-deterministic nature of the system under test, running test suites multiple times, and looking at the both the average aggregate pass/fail trend over time, and variablity of individual test failures is a good way to evaluate performance.

