
Our team had previously built a tool to investigate code quality from PR data. Building on this work, we set about finding a method to detect AI-written code, so we could investigate any potential differences in code quality between human and AI-written code.
During our time on this project, we learnt some important lessons, including just how hard it can be to detect AI-written code, and the importance of good-quality data when conducting research.
Binoculars
Binoculars is a zero-shot method of detecting LLM-generated text, meaning it is designed to be able to perform classification without having previously seen any examples of these categories. This has the advantage of allowing it to achieve good classification accuracy, even on previously unseen data.
A Binoculars score is essentially a normalized measure of how surprising the tokens in a string are to a Large Language Model (LLM). As you might expect, LLMs tend to generate text that is unsurprising to an LLM, and hence result in a lower Binoculars score. In contrast, human-written text often shows greater variation, and hence is more surprising to an LLM, which leads to higher Binoculars scores.
Because of this difference in scores between human and AI-written text, classification can be performed by selecting a threshold, and categorising text which falls above or below the threshold as human or AI-written respectively. Therefore, our team set out to investigate whether we could use Binoculars to detect AI-written code, and what factors might impact its classification performance.
Creating a Dataset
Before we could start using Binoculars, we needed to create a sizeable dataset of human and AI-written code, that contained samples of various tokens lengths. To achieve this, we developed a code-generation pipeline, which collected human-written code and used it to produce AI-written files or individual functions, depending on how it was configured.
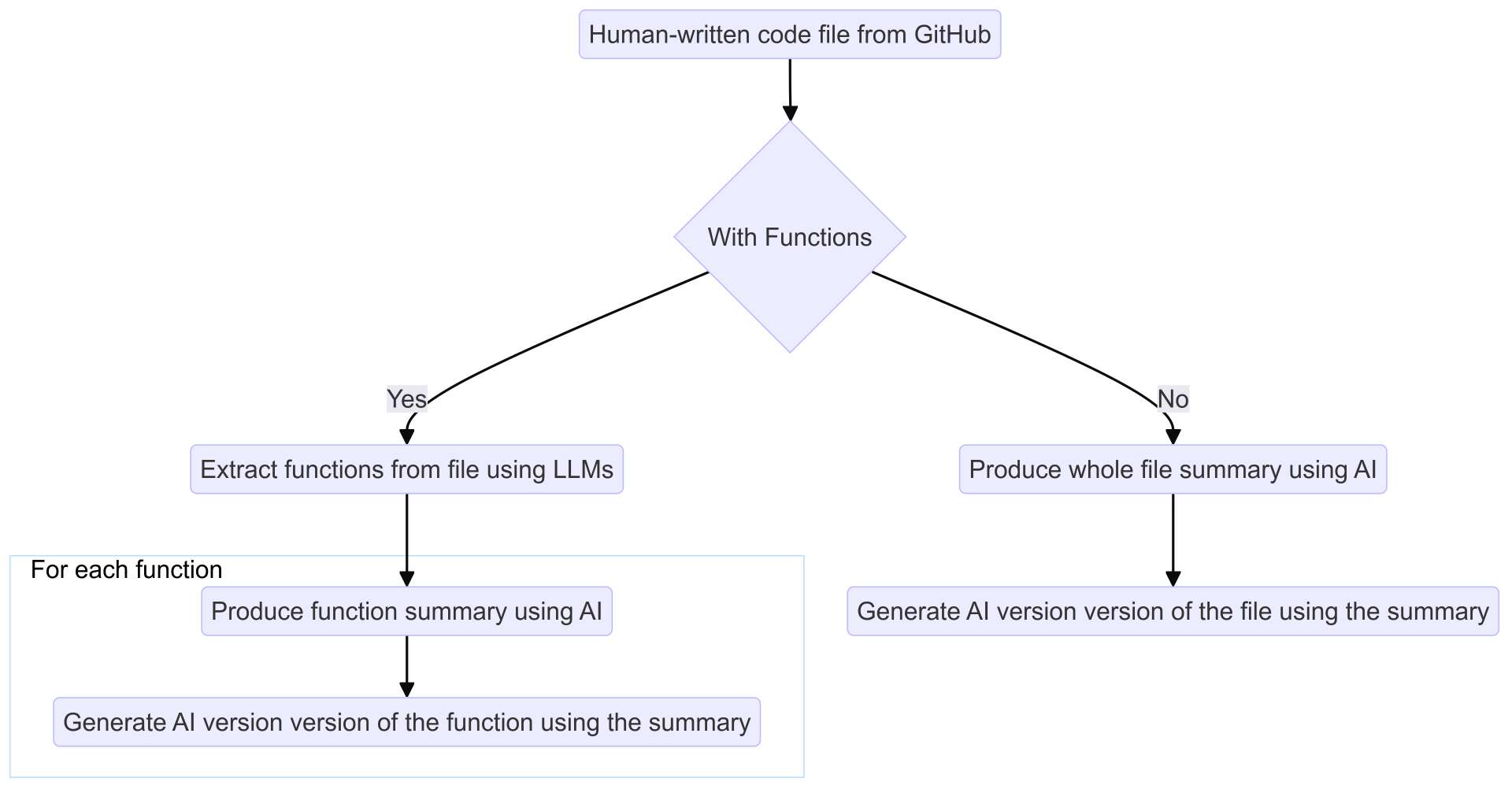 Our proposed pipeline for generating AI code samples
Our proposed pipeline for generating AI code samples
First, we provided the pipeline with the URLs of some GitHub repositories and used the GitHub API to scrape the files in the repositories. To ensure that the code was human written, we chose repositories that were archived before the release of Generative AI coding tools like GitHub Copilot.
If we were using the pipeline to generate functions, we would first use an LLM (GPT-3.5-turbo) to identify individual functions from the file and extract them programmatically. Using an LLM allowed us to extract functions across a large variety of languages, with relatively low effort.
Finally, we asked an LLM to produce a written summary of the file/function and used a second LLM to write a file/function matching this summary.
This pipeline automated the process of producing AI-generated code, allowing us to quickly and easily create the large datasets that were required to conduct our research.
Investigating Binoculars
With our datasets assembled, we used Binoculars to calculate the scores for both the human and AI-written code. We completed a range of research tasks to investigate how factors like programming language, the number of tokens in the input, models used calculate the score and the models used to produce our AI-written code, would affect the Binoculars scores and ultimately, how well Binoculars was able to distinguish between human and AI-written code.
This resulted in some exciting (and surprising) findings…
Effective Token Length
The original Binoculars paper identified that the number of tokens in the input impacted detection performance, so we investigated if the same applied to code.
From our code generation pipeline, we collected human and AI-written code files, written in a variety of programming languages, that were 25, 50, 100, 200, 300, 400, 500 tokens in length (+/- 10%). We then calculated the Binoculars score for each file.
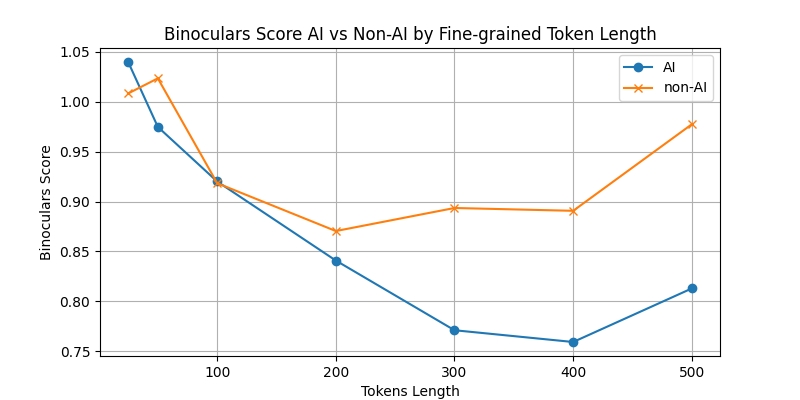 Average Binoculars score for AI and Non-AI written code, at each token length
Average Binoculars score for AI and Non-AI written code, at each token length
The above graph shows the average Binoculars score at each token length, for human and AI-written code. For inputs shorter than 150 tokens, there is little difference between the scores between human and AI-written code. However, from 200 tokens onward, the scores for AI-written code are generally lower than human-written code, with increasing differentiation as token lengths grow, meaning that at these longer token lengths, Binoculars would better be at classifying code as either human or AI-written.
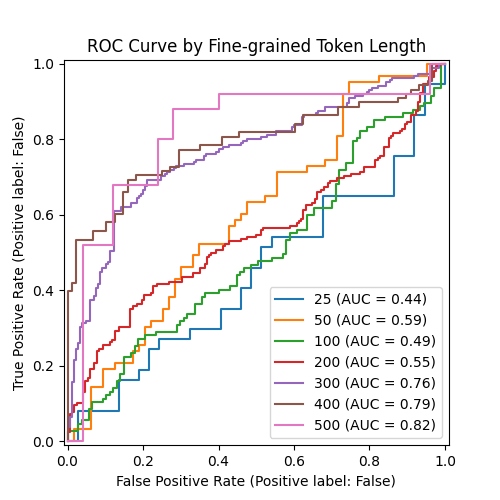
ROC Curve showing classification performance using various thresholds, for each token length
To get an indication of classification, we also plotted our results on a ROC Curve, which shows the classification performance across all thresholds. The AUC (Area Under the Curve) value is then calculated, which is a single value representing the performance across all thresholds.
The ideal ROC curve would be positioned towards the top left-hand corner of the chart, rising vertically from the origin (0,0) to the top-left corner (0,1) and then running horizontally to the top-right corner (1,1). This shape indicates that the classifier is perfect in distinguishing between the two classes, achieving an AUC value of 1.
The above ROC Curve shows the same findings, with a clear split in classification accuracy when we compare token lengths above and below 300 tokens. This, coupled with the fact that performance was worse than random chance for input lengths of 25 tokens, suggested that for Binoculars to reliably classify code as human or AI-written, there may be a minimum input token length requirement.
Models Used to Calculate Binoculars Scores
Here, we investigated the effect that the model used to calculate Binoculars score has on classification accuracy and the time taken to calculate the scores. Specifically, we wanted to see if the size of the model, i.e. the number of parameters, impacted performance. Although a larger number of parameters allows a model to identify more intricate patterns in the data, it does not necessarily result in better classification performance. Larger models come with an increased ability to remember the specific data that they were trained on. Because the models we were using had been trained on open-sourced code, we hypothesised that some of the code in our dataset may have also been in the training data. Therefore, although this code was human-written, it would be less surprising to the LLM, hence lowering the Binoculars score and decreasing classification accuracy.
Previously, we had used CodeLlama7B for calculating Binoculars scores, but hypothesised that using smaller models might improve performance. To investigate this, we tested 3 different sized models, namely DeepSeek Coder 1.3B, IBM Granite 3B and CodeLlama 7B using datasets containing Python and JavaScript code.
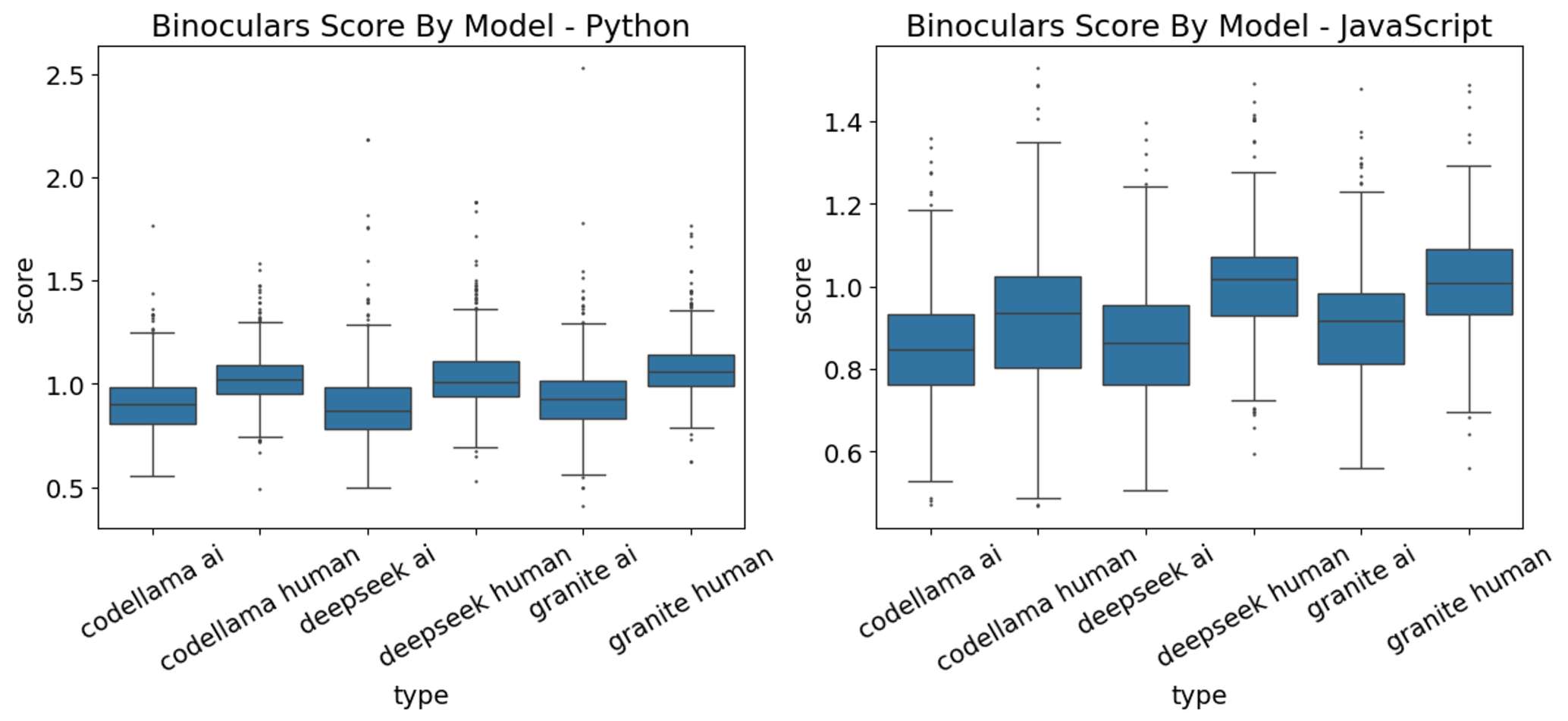 Box plots showing the distribution of Binoculars scores calculated using each model
Box plots showing the distribution of Binoculars scores calculated using each model
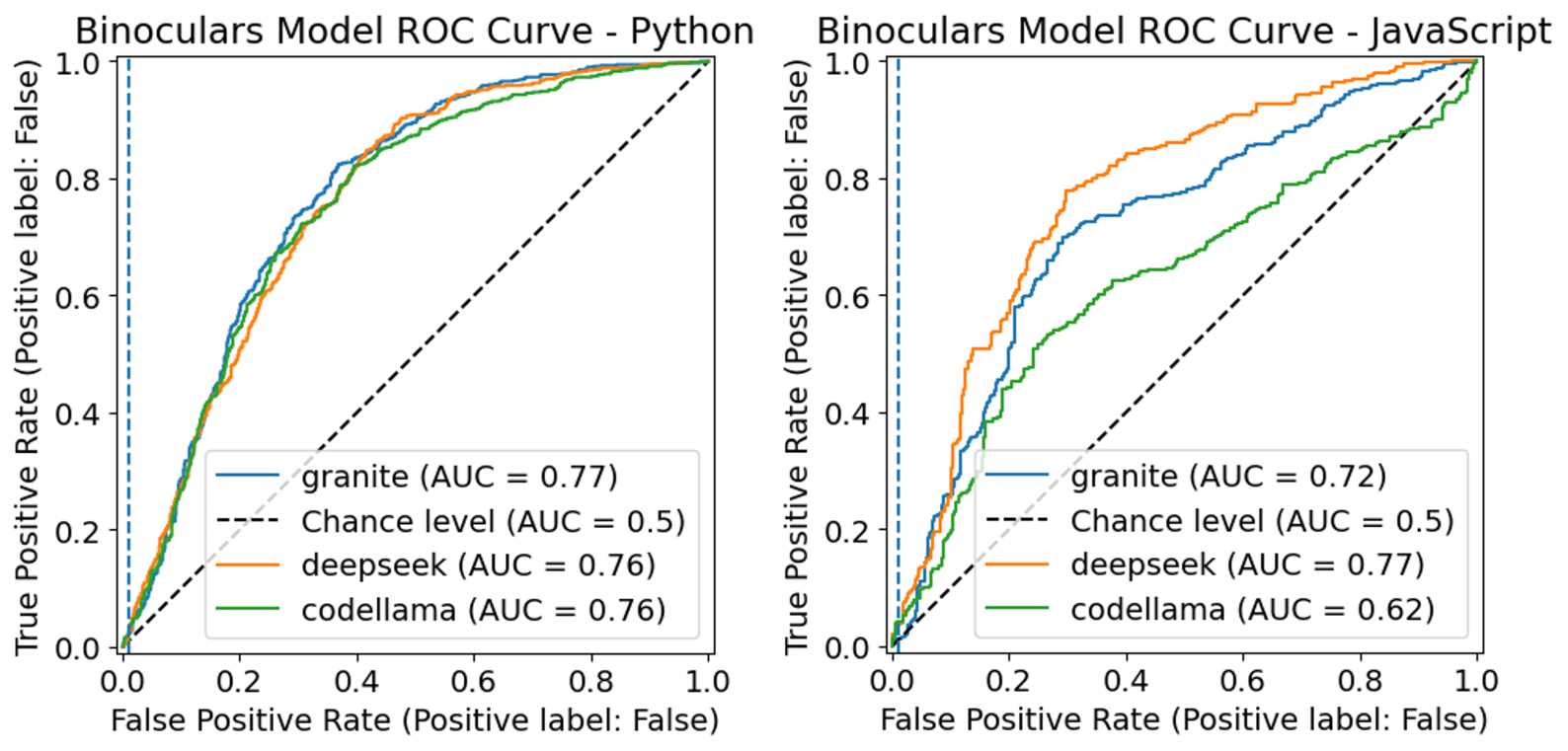 ROC Curve showing classification performance using various thresholds, for each model used to calculate Binoculars score
ROC Curve showing classification performance using various thresholds, for each model used to calculate Binoculars score
Our results showed that for Python code, all the models generally produced higher Binoculars scores for human-written code compared to AI-written code. We see the same pattern for JavaScript, with DeepSeek showing the largest difference. The ROC curves indicate that for Python, the choice of model has little impact on classification performance, while for JavaScript, smaller models like DeepSeek 1.3B perform better in differentiating code types.
| Model | Time for Human Code | Time for AI Code |
|---|---|---|
| DeepSeek Coder 1.3B | 6 min 51 s | 3 min 51 s |
| Granite Code 3B | 17 min 5 s | 8 min 37s |
| CodeLlama 7B | 35 min 28 s | 19 min 7 s |
Mean time to calculate Binoculars score for the dataset
Unsurprisingly, here we see that the smallest model (DeepSeek 1.3B) is around 5 times faster at calculating Binoculars scores than the larger models. From these results, it seemed clear that smaller models were a better choice for calculating Binoculars scores, resulting in faster and more accurate classification.
Binoculars at the Function Level
Previously, we had focussed on datasets of whole files. Next, we looked at code at the function/method level to see if there is an observable difference when things like boilerplate code, imports, licence statements are not present in our inputs.
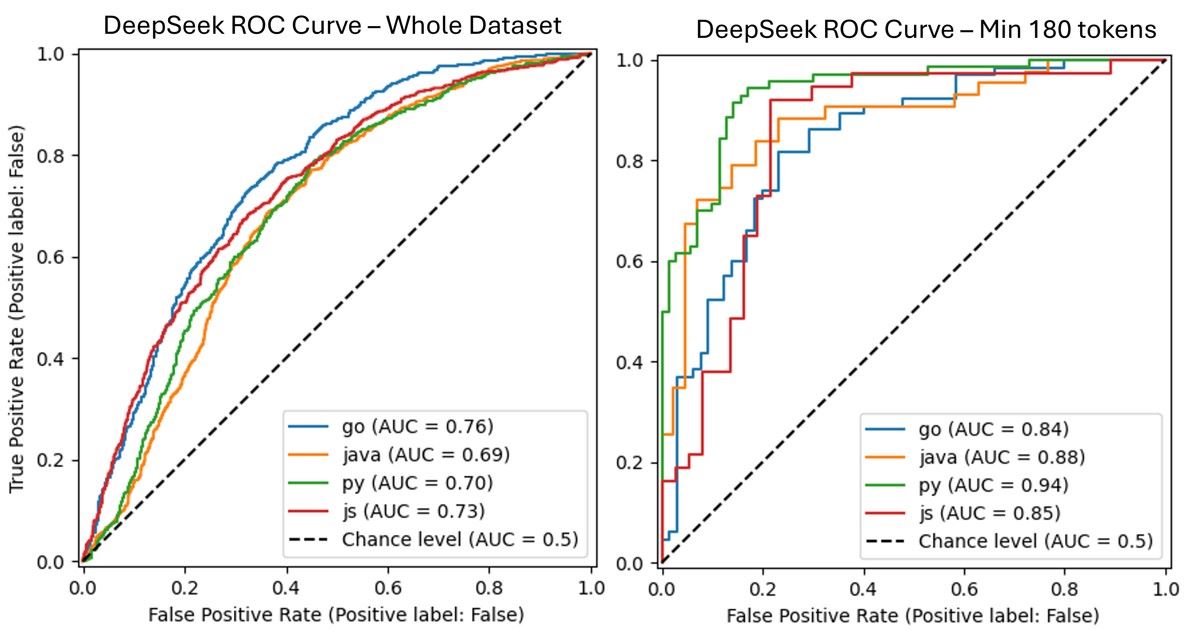 ROC Curve showing classification performance when calculating Binoculars score at the function level
ROC Curve showing classification performance when calculating Binoculars score at the function level
This resulted in a big improvement in AUC scores, especially when considering inputs over 180 tokens in length, confirming our findings from our effective token length investigation.
Models Used to Write Code:
Next, we set out to investigate whether using different LLMs to write code would result in differences in Binoculars scores. A dataset containing human-written code files written in a variety of programming languages was collected, and equivalent AI-generated code files were produced using GPT-3.5-turbo (which had been our default model), GPT-4o, ChatMistralAI, and deepseek-coder-6.7b-instruct.
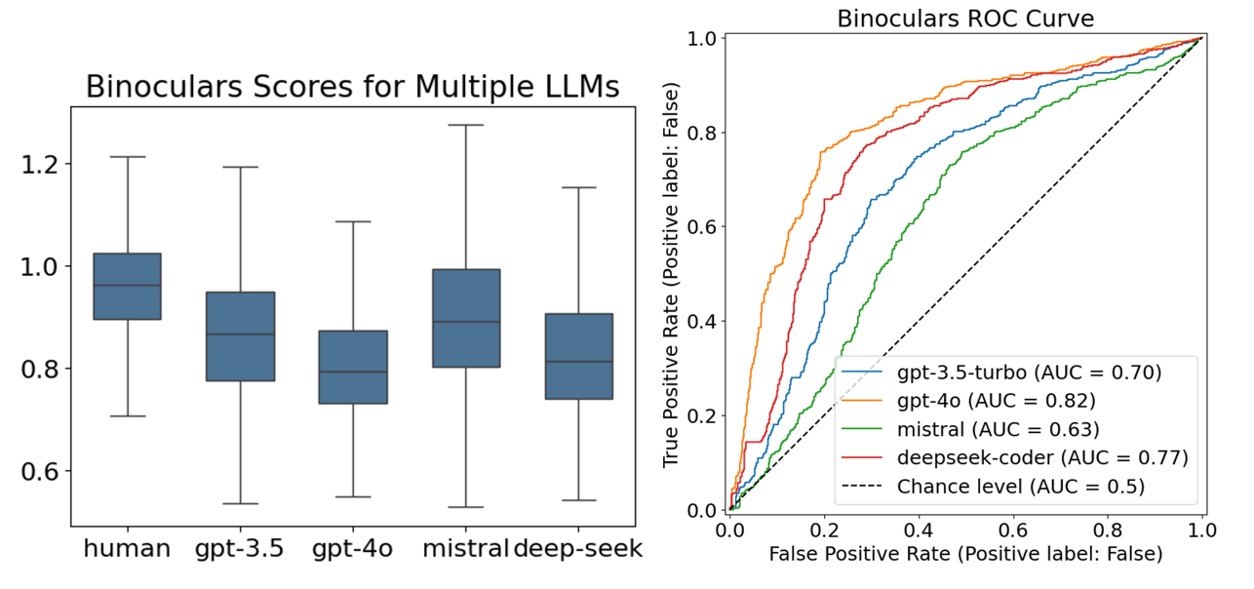
Amongst the models, GPT-4o had the lowest Binoculars scores, indicating its AI-generated code is more easily identifiable despite being a state-of-the-art model. The ROC curve further confirmed a better distinction between GPT-4o-generated code and human code compared to other models.
These findings were particularly surprising, because we expected that the state-of-the-art models, like GPT-4o would be able to produce code that was the most like the human-written code files, and hence would achieve similar Binoculars scores and be more difficult to identify.
Discovering a Problem
Although these findings were interesting, they were also surprising, which meant we needed to exhibit caution. We decided to reexamine our process, starting with the data. It could be the case that we were seeing such good classification results because the quality of our AI-written code was poor.
After taking a closer look at our dataset, we found that this was indeed the case. There were a few noticeable issues. Firstly, the code we had scraped from GitHub contained a lot of short, config files which were polluting our dataset. There were also a lot of files with long licence and copyright statements.
# pylint: disable=missing-docstring
__all__ = (
1, # [invalid-all-object]
lambda: None, # [invalid-all-object]
None, # [invalid-all-object]
)
An example of a human-written Python config file from our dataset
Additionally, in the case of longer files, the LLMs were unable to capture all the functionality, so the resulting AI-written files were often filled with comments describing the omitted code.
public class NestedFunctionCalls {
public void performQuery() {
equiJoinClause(
anyTree(
join("L_ORDERKEY", "O_ORDERKEY"),
join("P_PARTKEY", "L_PARTKEY")
),
filter("LINEITEM_WITH_RETURNFLAG_TABLESCAN", "L_RETURNFLAG = 'R'"),
filter("ORDERS_WITH_SHIPPRIORITY_TABLESCAN", "O_SHIPPRIORITY >= 10")
);
}
public void equiJoinClause(Object... joins) {
// Implementation of equiJoinClause
}
public void anyTree(Object... nodes) {
// Implementation of anyTree
}
public void join(String table1, String table2) {
// Implementation of join
}
An example of a code snippet, taken from an AI-written Java file from our dataset
Back to the Drawing Board
With the source of the issue being in our dataset, the obvious solution was to revisit our code generation pipeline.
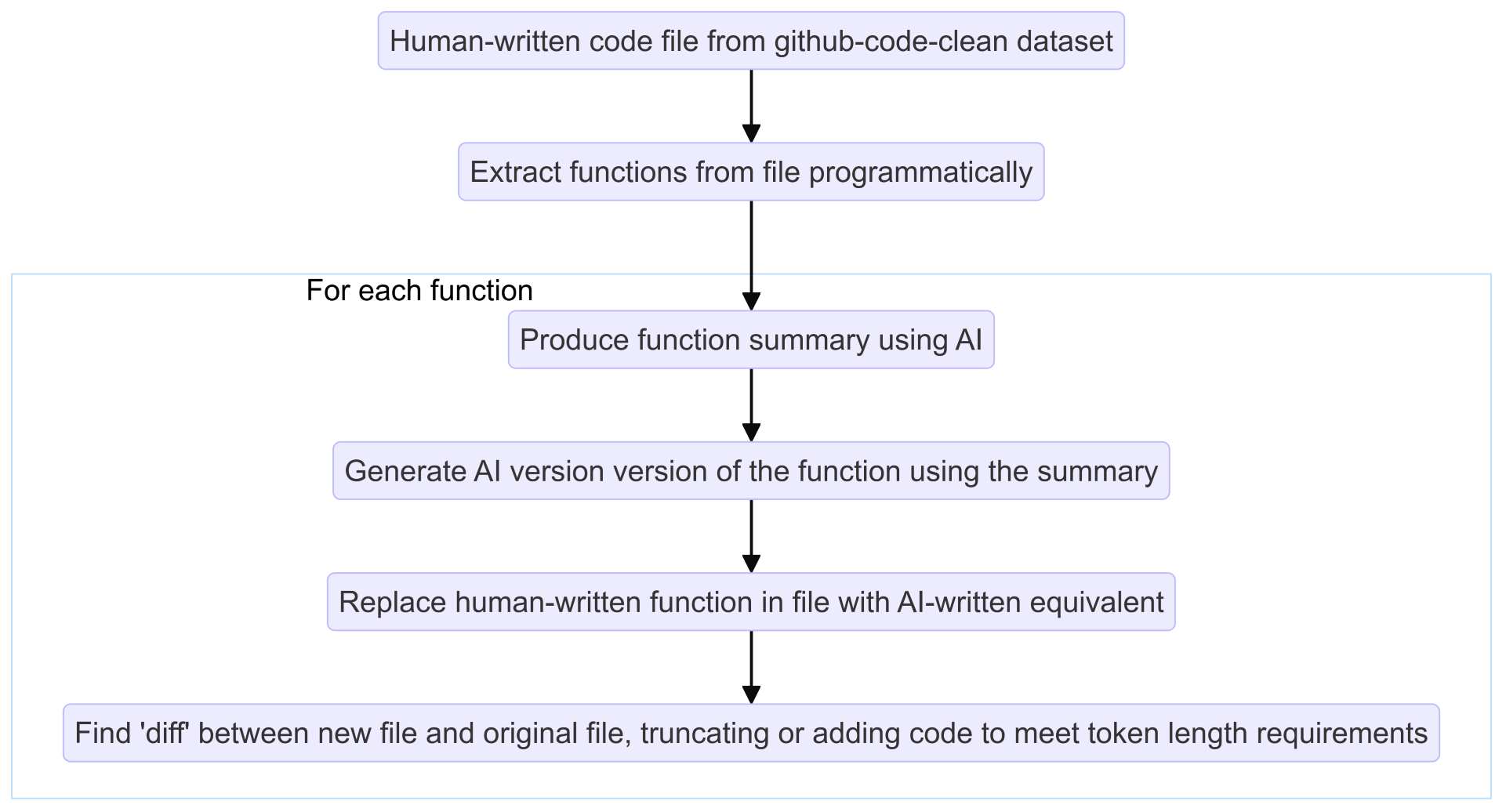 Our new pipeline for generating AI code samples
Our new pipeline for generating AI code samples
First, we swapped our data source to use the github-code-clean dataset, containing 115 million code files taken from GitHub. These files had been filtered to remove files that are auto-generated, have short line lengths, or a high proportion of non-alphanumeric characters.
Using this dataset posed some risks because it was likely to be a training dataset for the LLMs we were using to calculate Binoculars score, which could lead to scores which were lower than expected for human-written code. However, the size of the models were small compared to the size of the github-code-clean dataset, and we were randomly sampling this dataset to produce the datasets used in our investigations. Therefore, it was very unlikely that the models had memorized the files contained in our datasets. Therefore, the benefits in terms of increased data quality outweighed these relatively small risks.
We had also identified that using LLMs to extract functions wasn’t particularly reliable, so we changed our approach for extracting functions to use tree-sitter, a code parsing tool which can programmatically extract functions from a file.
For each function extracted, we then ask an LLM to produce a written summary of the function and use a second LLM to write a function matching this summary, in the same way as before.
Then, we take the original code file, and replace one function with the AI-written equivalent. We then take this modified file, and the original, human-written version, and find the “diff” between them. Finally, we either add some code surrounding the function, or truncate the function, to meet any token length requirements.
Repeating our Research
With our new dataset, containing better quality code samples, we were able to repeat our earlier research. If we saw similar results, this would increase our confidence that our earlier findings were valid and correct.
However, with our new dataset, the classification accuracy of Binoculars decreased significantly. Although this was disappointing, it confirmed our suspicions about our initial results being due to poor data quality.
With our new pipeline taking a minimum and maximum token parameter, we started by conducting research to discover what the optimum values for these would be. Because it showed better performance in our initial research work, we started using DeepSeek as our Binoculars model.
Effective Token Length
Attempt 1:
In our first iteration, we took all the functions in our dataset, and produced datasets containing 16, 32, 64, 128, 256, and 512, by setting the minimum and maximum token lengths to +/- 10% of the target size.
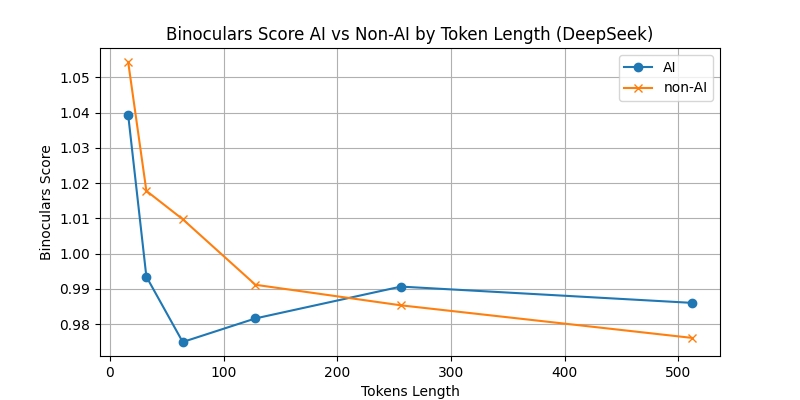
Average Binoculars score for AI and Non-AI written code, at each token length
This chart shows a clear change in the Binoculars scores for AI and non-AI code for token lengths above and below 200 tokens. Below 200 tokens, we see the expected higher Binoculars scores for non-AI code, compared to AI code. However, above 200 tokens, the opposite is true.
| Non-AI | AI | |
|---|---|---|
| Lower Quartile | 33.0 | 36.0 |
| Median | 67.0 | 68.0 |
| Upper Quartile | 139.0 | 105.0 |
Distribution of number of tokens for human and AI-written functions.
We hypothesise that this is because the AI-written functions generally have low numbers of tokens, so to produce the larger token lengths in our datasets, we add significant amounts of the surrounding human-written code from the original file, which skews the Binoculars score.
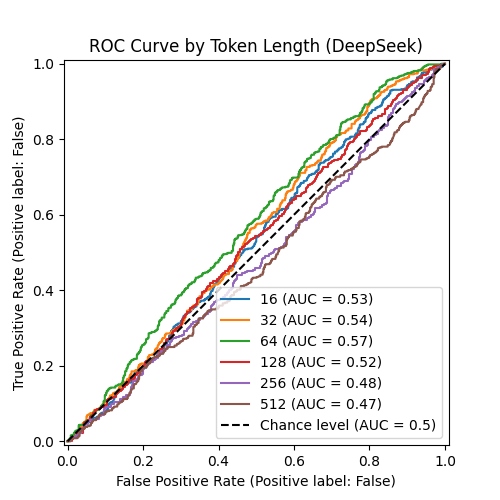
ROC Curve showing classification performance using various thresholds, for each token length
Looking at the AUC values, we see that for all token lengths, the Binoculars scores are almost on par with random chance, in terms of being able to distinguish between human and AI-written code. It is particularly bad at the longest token lengths, which is the opposite of what we saw initially.
Attempt 2:
Due to the poor performance at longer token lengths, here, we produced a new version of the dataset for each token length, in which we only kept the functions with token length at least half of the target number of tokens. This meant that in the case of the AI-generated code, the human-written code which was added did not contain more tokens than the code we were examining.
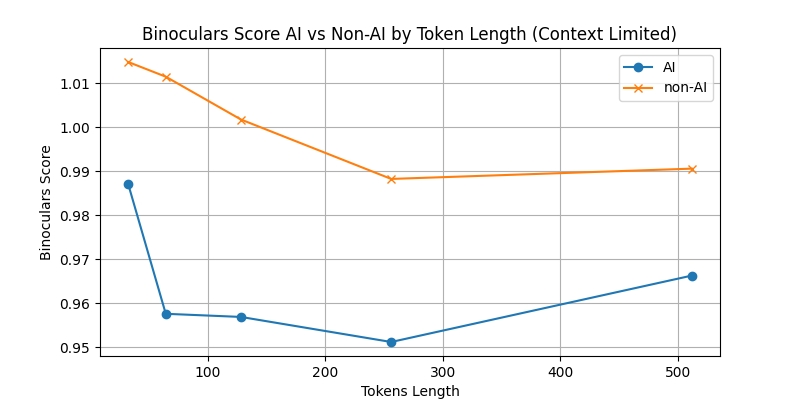
Average Binoculars score for AI and Non-AI written code when the amount of context is limited, at each token length
Here, we see a clear separation between Binoculars scores for human and AI-written code for all token lengths, with the expected result of the human-written code having a higher score than the AI-written. However, this difference becomes smaller at longer token lengths.
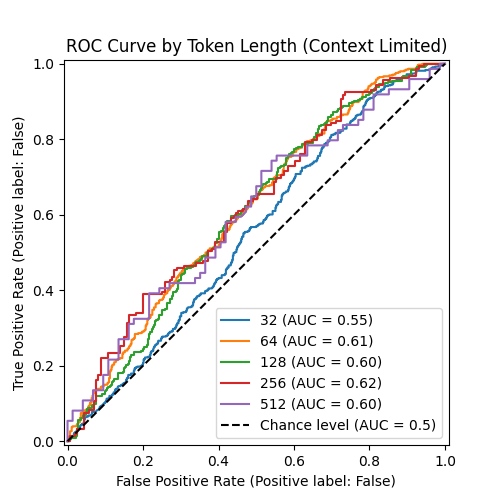
ROC Curve showing classification performance when the amount of context is limited, for each token length
The chart reveals a key insight. The AUC values have improved compared to our first attempt, indicating only a limited amount of surrounding code that should be added, but more research is needed to identify this threshold.
Lessons Learnt
Although our research efforts didn’t lead to a reliable method of detecting AI-written code, we learnt some valuable lessons along the way.
The foundation of good research is good quality data
Although data quality is difficult to quantify, it is crucial to ensure any research findings are reliable. As evidenced by our experiences, bad quality data can produce results which lead you to make incorrect conclusions. It can be helpful to hypothesise what you expect to see. That way, if your results are surprising, you know to reexamine your methods.
Automation can be a double-edged sword
Automation can be both a blessing and a curse, so exhibit caution when you’re using it. Automation allowed us to rapidly generate the huge amounts of data we needed to conduct this research, but by relying on automation too much, we failed to spot the issues in our data. In hindsight, we should have dedicated more time to manually checking the outputs of our pipeline, rather than rushing ahead to conduct our investigations using Binoculars.
Although our data issues were a setback, we had set up our research tasks in such a way that they could be easily rerun, predominantly by using notebooks. Research process often need refining and to be repeated, so should be developed with this in mind.
Conclusion
Despite our promising earlier findings, our final results have lead us to the conclusion that Binoculars isn’t a viable method for this task. Reliably detecting AI-written code has proven to be an intrinsically hard problem, and one which remains an open, but exciting research area.
Many thanks to the AI Repository Analysis team including Chris Price, Diana Prahoveanu, James Strong, Jonny Spruce, Matthew Beanland, and Nick Gillen for all their work on this research.

